過去我在處理 golang 在作業系統上呼叫 process 的問題,是利用 stackoverflow 的範例程式碼。stackoverflow 的範例有考慮到 process 可能會執行太久,所以有處理 timeout 的問題,但是,少考慮到了一個問題: child process 和 grand child process 的問題。
當 golang 呼叫的外部 process 因為 timeout 的因素,而被 kill 的時候,如果只用 process id 去 kill ,而這個外部 process 已經有啟動了 child process 的話,就會造成它的 child process 都變成 orphan process 的問題。因為這些 child process 並不會因為 parent process 被 kill 而自動結束。
有考慮上述問題的有效作法,啟動外部的 process 時,要設定一個新的 process session id。如此,讓新增的 process 與 child process, grand child process 都使用新的 process session id 。當 timeout 發生的時候,對 process id 取負值後發送 kill signal 就可以將這些外部的 process 一次全部清除完畢。
Wednesday, November 23, 2016
Monday, November 21, 2016
influxdb vs Star Schema
工作上會用到 influxdb ,最初就是把文件看一看,然後寫成心得。
使用influxdb的重要觀念
使用influxdb的重要觀念
(a) 可以把 influxdb 類比成一般的資料庫
influxdb
|
一般的DB
|
|---|---|
| measurement |
table
|
| time | row |
| fields, tags | column |
field 和tags的差異: field是required, tag是optional。field沒有建立index。tag會自動建立index。
如何決定,某一個值應該使用field或是tag來儲存?
usage
|
field
|
tag
|
|---|---|---|
| case1 | if you plan to use them with GROUP BY() | |
| case2 | if you plan to use them with an InfluxQL function | |
| case3 | if you need them to be something other than a string |
然而,過了一陣子之後,我卻重新思考了這個問題。問題思考的起始點是這樣子:「如果我要用 mysql 這類的 relational database 來做 time series database 的用途,我的 schema 該如何設計呢?」
查了一些網站之後,隨即發現,原來我思考的這個問題,根本就是 time series database 設計的重要問題之一,連維基百科的條目,都有提到如何用 relational database 來模擬 time series database 。而這一類的「時間序列資料」的特性就是「多維度」。多維度的資料如果要求要高效能做 OLAP = On-Line Analytical Processing ,最合用的 database schema 就是 Star Schema 。
理解了適合 time series database 的 schema 是 star schema 之後,要來設計 influxdb 的 schema ,似乎也就更清楚了一些。
Wednesday, November 16, 2016
Restful API design
在公司最近進行的項目,是 API 的設計。網路上已經有許多 Restful API best practice 的文章了。所以這邊我寫的是個人親手踩過的坑。
(1) Gzip compression support
http 要支援 Gzip 的話,在公司的架構算是一件容易的事,因為真實的 API server 前,還有一台 nginx 在做 reverse proxy 。所以,只需要設定 nginx ,讓 nginx 可以做 gzip 就可以了。並不需要從 API server 的源頭端改下去。
(2) 送出的資料量如果大的話,要記得做 pagination 。最好的作法應該使用定義於 RFC 5988 的 Link header ,因為這樣子就不必將 link header 的資訊放在 body 裡頭。
(3) 如果 API 的參數有時間的參數,考慮使用 Unix time 格式或是 ISO-8601。Unix time 是我本來就知道的。 ISO-8601 也是標準格式,我則是查了一段時間才搞懂。

後記:
讀過了 Restful API best practices 之後,我認為其中最重要的精神應該還是不要重造輪子。能利用 http 既有 header 來做的功能,就儘量利用 http 來做。如此才可以將複雜度(complexity)隱藏在 http 傳輸協定裡。比方說:
1 資料壓縮 → http 的 header => Accept-Encoding: gzip
2 認証 → http digest authentication
3 合理使用量 → http rate limit
4 分頁(pagination) → http link header
5 加密 → https
6 CRUD 不同的操作 → http method : put, delete, get, post
7 caching → ETag, Last-Modified
8 exception handling → http status code
(1) Gzip compression support
http 要支援 Gzip 的話,在公司的架構算是一件容易的事,因為真實的 API server 前,還有一台 nginx 在做 reverse proxy 。所以,只需要設定 nginx ,讓 nginx 可以做 gzip 就可以了。並不需要從 API server 的源頭端改下去。
gzip on; gzip_types application/json;
(2) 送出的資料量如果大的話,要記得做 pagination 。最好的作法應該使用定義於 RFC 5988 的 Link header ,因為這樣子就不必將 link header 的資訊放在 body 裡頭。
(3) 如果 API 的參數有時間的參數,考慮使用 Unix time 格式或是 ISO-8601。Unix time 是我本來就知道的。 ISO-8601 也是標準格式,我則是查了一段時間才搞懂。

後記:
讀過了 Restful API best practices 之後,我認為其中最重要的精神應該還是不要重造輪子。能利用 http 既有 header 來做的功能,就儘量利用 http 來做。如此才可以將複雜度(complexity)隱藏在 http 傳輸協定裡。比方說:
1 資料壓縮 → http 的 header => Accept-Encoding: gzip
2 認証 → http digest authentication
3 合理使用量 → http rate limit
4 分頁(pagination) → http link header
5 加密 → https
6 CRUD 不同的操作 → http method : put, delete, get, post
7 caching → ETag, Last-Modified
8 exception handling → http status code
Monday, November 14, 2016
寫 python 用的環境配置
大概是因為前陣子寫 golang 時,受到 golang 的啟發後,再也回不去了。最近又開始寫一些 python ,馬上就覺得好像少了一些什麼東西?
仔細一想,原來少了跟 vim 搭配的 style checker plugin 。於是我立刻找了兩套來安裝。兩套都用看看,才知道哪一套比較順手。一套是 autopep8 對應的 vim plugin,另一套是 flake8 對應的 vim plugin 。前者檢查略鬆。後者檢查比較緊,但是只差一些些而已。
另外,還有一個很重要的,是 vim plugin 無法解決的。變數、類別取名的規範。這個只能靠頭腦去記了。
Guidelines derived from Guido's Recommendations
仔細一想,原來少了跟 vim 搭配的 style checker plugin 。於是我立刻找了兩套來安裝。兩套都用看看,才知道哪一套比較順手。一套是 autopep8 對應的 vim plugin,另一套是 flake8 對應的 vim plugin 。前者檢查略鬆。後者檢查比較緊,但是只差一些些而已。
另外,還有一個很重要的,是 vim plugin 無法解決的。變數、類別取名的規範。這個只能靠頭腦去記了。
Guidelines derived from Guido's Recommendations
| Type | Public | Internal |
|---|---|---|
| Packages | lower_with_under | |
| Modules | lower_with_under | _lower_with_under |
| Classes | CapWords | _CapWords |
| Exceptions | CapWords | |
| Functions | lower_with_under() | _lower_with_under() |
| Global/Class Constants | CAPS_WITH_UNDER | _CAPS_WITH_UNDER |
| Global/Class Variables | lower_with_under | _lower_with_under |
| Instance Variables | lower_with_under | _lower_with_under (protected) or __lower_with_under (private) |
| Method Names | lower_with_under() | _lower_with_under() (protected) or __lower_with_under() (private) |
| Function/Method Parameters | lower_with_under | |
| Local Variables | lower_with_under |
Simplicity can yield functionality, robustness, speed and space
Simplicity can yield functionality, robustness, speed and space. 這段話出自 programming pearls 一書。很奇怪,我學程式設計也滿久了,漸漸才理解程式設計最核心的問題,就是把本來複雜的問題加以化簡。可以舉的例子太多了,用一個困擾我許久的問題來解釋這個概念。
以前我要做網站時,就會遇到疑問,到底要用:
(1) drupal, joomla, wordpress 等 CMS 的解法
(2) RoR, Django, laravel 等 framework 的解法
(3) 全手刻後端 + javascript 前端
而我以前待過的公司一連兩間都是採用第三種解法。其中最主要的原因之一,多少是因為精通 framework 的工程師不是那麼好找。沒有信心之下,大家還是決定先直接手刻後端的程式算了。總不能為了還不清楚會如何發展的規格,冒然引進一大堆,工程師自己都無法理解的 middle ware 。以前我覺得好像這樣子不是很好的解法,總覺得這樣子的決定,似乎是在工程師本身對各種工具掌握度不足而做的選擇。
後來,又有一些新的名詞冒了出來:
(1) API centric design: 後端只提供 Restful API。前端完全用 javascript 來做。
(2) micro services: 後端不要做成一隻程式,而是做成好幾隻小小的程式。每一個程式有各自的功能,彼此之間用 RPC/MQ 來溝通。
(3) Headless Drupal: 後端用 Drupal 來做,但是只提供 Restful API 給前端,前端還是用 javascript 來做。
看到這些新的名詞逐漸流行,我想應該也是很多人也跟我有類似的看法。需要解決的網站開發問題沒有那麼複雜,用簡單一點的 library, framework ,一切會單純許多。「簡單」才是最重要的事。
最近我因為工作需要,一連用了 nodejs 和 python 寫了兩個 API server。nodejs 我用的是 expressjs。python 我用的是 bottle 。應該都是最簡單的 framework 了。大概因為太簡單了,我寫完沒有多久,就完全忘記怎麼寫了。XD
以前我要做網站時,就會遇到疑問,到底要用:
(1) drupal, joomla, wordpress 等 CMS 的解法
(2) RoR, Django, laravel 等 framework 的解法
(3) 全手刻後端 + javascript 前端
而我以前待過的公司一連兩間都是採用第三種解法。其中最主要的原因之一,多少是因為精通 framework 的工程師不是那麼好找。沒有信心之下,大家還是決定先直接手刻後端的程式算了。總不能為了還不清楚會如何發展的規格,冒然引進一大堆,工程師自己都無法理解的 middle ware 。以前我覺得好像這樣子不是很好的解法,總覺得這樣子的決定,似乎是在工程師本身對各種工具掌握度不足而做的選擇。
後來,又有一些新的名詞冒了出來:
(1) API centric design: 後端只提供 Restful API。前端完全用 javascript 來做。
(2) micro services: 後端不要做成一隻程式,而是做成好幾隻小小的程式。每一個程式有各自的功能,彼此之間用 RPC/MQ 來溝通。
(3) Headless Drupal: 後端用 Drupal 來做,但是只提供 Restful API 給前端,前端還是用 javascript 來做。
看到這些新的名詞逐漸流行,我想應該也是很多人也跟我有類似的看法。需要解決的網站開發問題沒有那麼複雜,用簡單一點的 library, framework ,一切會單純許多。「簡單」才是最重要的事。
最近我因為工作需要,一連用了 nodejs 和 python 寫了兩個 API server。nodejs 我用的是 expressjs。python 我用的是 bottle 。應該都是最簡單的 framework 了。大概因為太簡單了,我寫完沒有多久,就完全忘記怎麼寫了。XD
Sunday, November 6, 2016
db patch
公司的系統一直在增加功能,資料庫也會不斷地更改 schema 。然而,已經存在生產環境 (production environment) 中的資料庫,卻不能直接套用新的 schema ,而是要用 patch 的方式,將舊的 schema 改成新的 schema 。於是開發的工作就會有一項,是要比較新舊的 schema 來寫出 transformation script 。
很幸運的是,這個似乎已經是前人研究過的問題了。有現成的工具可以使用。
(2) 如果因為遇到一些奇奇怪怪 python library 的問題導致裝不起來時,也可以用考慮使用 docker 來迴避安裝的困難。
很幸運的是,這個似乎已經是前人研究過的問題了。有現成的工具可以使用。
(1) 安裝 mysqldiff
$ sudo apt-get install mysql-utilities
(2) 如果因為遇到一些奇奇怪怪 python library 的問題導致裝不起來時,也可以用考慮使用 docker 來迴避安裝的困難。
$ docker pull samfulton/mysql-utilities
$ docker run -ti samfulton/mysql-utilities
(3) 使用的實例1:比較兩張資料表
$ mysqldiff --server1=root:password@10.20.30.40 \ boss.contacts:coss.contacts \
--difftype=sql -v
(4)使用的實例2:比較兩個完整的資料庫,且遇到錯誤不停止,繼續比較。 $ mysqldiff --server1=root:password@10.20.30.40 \ boss:coss \ --difftype=sql -v --forceFriday, November 4, 2016
excel 表格的半自動處理
朋友是業務,業務的工作之一,就是整理要給客戶的報價單。
下圖,就是朋友的工作。左邊四個欄位是原始資料。最右邊的output 欄位是他要透過查表,才能寫出公司的 part number 型號。
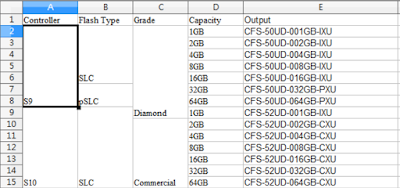 朋友詢問我,是否有辦法可以幫他寫個查表的程式,可以讓他不需要依賴人力來處理愚蠢的查表工作。我構思了一下,又覺得有困難。原因是,他公司的 excel 表格,合併儲存格的部分,相當不規律,我很難用 excel 轉 csv 的方式,做統一的處理。但是,仔細思考之後,發現其實可以用半自動化的方式來解這個問題。
朋友詢問我,是否有辦法可以幫他寫個查表的程式,可以讓他不需要依賴人力來處理愚蠢的查表工作。我構思了一下,又覺得有困難。原因是,他公司的 excel 表格,合併儲存格的部分,相當不規律,我很難用 excel 轉 csv 的方式,做統一的處理。但是,仔細思考之後,發現其實可以用半自動化的方式來解這個問題。

怎樣算是半自動解呢?由於解除儲存格,將儲存格填滿的部分,對於業務來說,其實是很容易的,也不太耗時間,這個部分就還是由人手工來做。我只用程式處理最後的查表工作。
同時,仔細想想,用 script language 去處理 csv 檔,就會需要朋友手動做匯出。其實這個操作對一般人很不直覺。
既然需要的資料都已經在同一個 row 上了,就寫了一隻使用者自訂函數來處理。
在 John Bentley 所著 Programming Pearls 一書中,也有一段話寫到相似的解題想法 ---
Keeping track of our organization's budget looked difficult to me. Out of habit, I would have built a large program for the job, with a clunky user interface. The next programmer took a broader view, and implemented the program as a spreadsheet, supplemented by a few functions in Visual Basic. The interface was totally natural for the accounting people who were the main users.
下圖,就是朋友的工作。左邊四個欄位是原始資料。最右邊的output 欄位是他要透過查表,才能寫出公司的 part number 型號。


怎樣算是半自動解呢?由於解除儲存格,將儲存格填滿的部分,對於業務來說,其實是很容易的,也不太耗時間,這個部分就還是由人手工來做。我只用程式處理最後的查表工作。
同時,仔細想想,用 script language 去處理 csv 檔,就會需要朋友手動做匯出。其實這個操作對一般人很不直覺。
既然需要的資料都已經在同一個 row 上了,就寫了一隻使用者自訂函數來處理。
在 John Bentley 所著 Programming Pearls 一書中,也有一段話寫到相似的解題想法 ---
Keeping track of our organization's budget looked difficult to me. Out of habit, I would have built a large program for the job, with a clunky user interface. The next programmer took a broader view, and implemented the program as a spreadsheet, supplemented by a few functions in Visual Basic. The interface was totally natural for the accounting people who were the main users.
Thursday, November 3, 2016
[SQL] 對一張 table 的 multiple rows 做更新
公司的源碼裡,有一段程式碼,被公司的資深工程師挑出來說需要重構。本來的程式碼做的事情是: 「對一張 table 的 multiple rows 做更新的動作」。
原始的寫法如下:
1 用 ORM 將整張 table 讀入記憶體,每一 row 恰好對應一個物件。
2 跑迴圈,對物件做檢查,如果合乎條件,則做更新。
上述的寫法在資料量少的時候沒有影響,然而,在資料量大的時候,效能就會極差。因為多做了將整張 table 讀入記憶體的動作。比較好的重構版如下:
1 將要寫入 table 的資料,先寫入一張 temporary table。
例如:
CREATE TEMPORARY TABLE IF NOT EXISTS table2 AS (SELECT * FROM table1)
2.1 開啟 transaction
2.2 基於 temporary table 的值,用 join 操作來更新目的地的 table
例如:
3 丟棄 temporary table
新的寫法,是將要用來寫入 table 的值先寫入資料庫裡,再透過 SQL 的指令去做資料的更新。如此,大量減少了記憶體與資料庫之間的資料搬移。對於數據量大的情況,就會有效能的大幅改進。
註:新的寫法中,其實可以不用加上 transaction ,因為只有一個 update 的操作。然而考慮實務上的程式,常常會有超過一個 update 的操作。當兩個 update 操作有必要緊接著完成,不可以在中間被其它的 session 插入讀取的動作,就會需要 transaction 。
原始的寫法如下:
1 用 ORM 將整張 table 讀入記憶體,每一 row 恰好對應一個物件。
2 跑迴圈,對物件做檢查,如果合乎條件,則做更新。
上述的寫法在資料量少的時候沒有影響,然而,在資料量大的時候,效能就會極差。因為多做了將整張 table 讀入記憶體的動作。比較好的重構版如下:
1 將要寫入 table 的資料,先寫入一張 temporary table。
例如:
CREATE TEMPORARY TABLE IF NOT EXISTS table2 AS (SELECT * FROM table1)
2.1 開啟 transaction
2.2 基於 temporary table 的值,用 join 操作來更新目的地的 table
例如:
UPDATE TABLE1
JOIN TABLE2
ON TABLE1.SUBST_ID = TABLE2.SERIAL_ID
SET TABLE2.BRANCH_ID = TABLE1.CREATED_ID;3 丟棄 temporary table
新的寫法,是將要用來寫入 table 的值先寫入資料庫裡,再透過 SQL 的指令去做資料的更新。如此,大量減少了記憶體與資料庫之間的資料搬移。對於數據量大的情況,就會有效能的大幅改進。
註:新的寫法中,其實可以不用加上 transaction ,因為只有一個 update 的操作。然而考慮實務上的程式,常常會有超過一個 update 的操作。當兩個 update 操作有必要緊接著完成,不可以在中間被其它的 session 插入讀取的動作,就會需要 transaction 。
Subscribe to:
Posts (Atom)